


Source Of Traffic is always the hottest topic in Digital Analytics. Though Marketing Channels are popular in identifying the source, the configuration is not done out of box but are to be set by the companies themselves. So, it is necessary to understand how the Traffic Sources Reports such as Referrers, Referring Domains, Original Referring Domains, Search Engines (All, Paid & Organic), Search Keywords (All, Paid & Organic) & Referrer Type work and it’s time to uproot the concepts of all these reports.
Below are the key notes to consider before we discuss the individual reports in Traffic Sources.
– Report line items are captured during the first page of visit or whenever the referrer domain is not the one specified in our ‘Internal URL Filters’ (i.e. Where our visitors came from before they arrived at our site) and have default persistence of visit unless it is overwritten.
– We cannot custom classify any of the reports in Traffic Sources but only be segmented.
– Basic understanding on ‘Internal URL Filters’ and ‘Paid Search Detection Rules’ are known.
Referrers
Referrer(s.referrer (r)) is the primary identifier for Traffic Sources and all other Traffic Sources Reports are derived or computed from the same. Adobe Analytics automatically sets this variable to document.referrer unless you override it manually. Considering terryn.com and winter.com are our own domains and added to the ‘Internal URL Filters’, here is how the referrers are computed in Adobe Analytics for the below scenario.
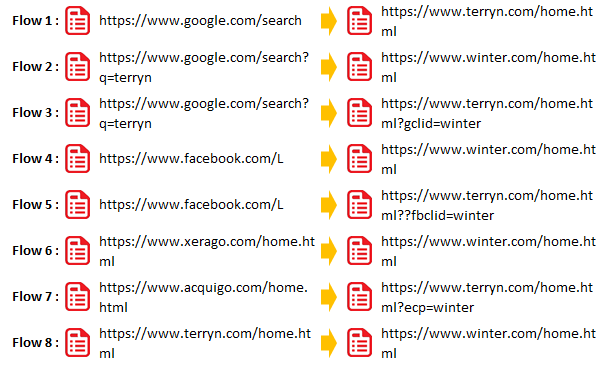
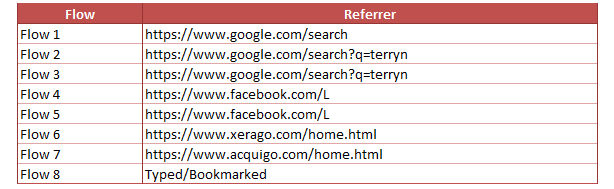
When our domain is loaded directly (Flow 8), the referrer will be empty and identified as ‘Typed/Bookmarked’. We should therefore never see our own domains in the referrer report in an ideal world.
However for flow 8, if we are inactive for more than 30 minutes after loading the first URL, the session will be refreshed. So, if we navigate to the second URL, Adobe Analytics will consider the second URL as the first page of visit and capture the referrer i.e. https://www.terryn.com/home.html.
There are few more cases such as improper Internal URL Filters setup, redirections, first page of visit without Adobe Analytics code, long videos without periodic pings etc., will also result in our own domains becoming available in referrer report. Therefore, we see our own domains in the referrer report in real-world conditions, but should not contribute healthy traffic.
Even if the visitor comes to the site multiple times during a session (before the visit expires), referrer is captured every time and thus a single visit can have multiple referrers.
Referring Domains
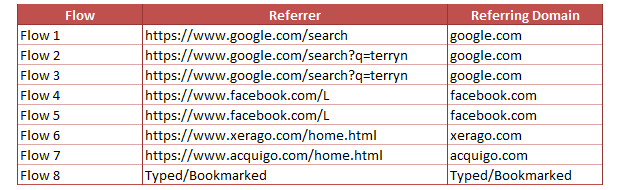
Understanding Referring Domains Report is easy. Adobe is just going to classify the domain of the referrer to report under Referring Domains.
Original Referring Domains
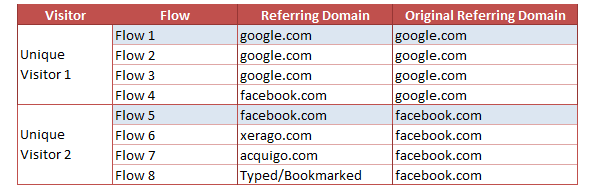
Original Referring Domains are based on the visitors instead of visits. The first referring domain for the visitor is saved and persisted for the visitor’s lifetime. Even if the visitor comes to the site multiple times during a session, the original referring domain is preserved. Considering the flows 1 to 4 are from one unique visitor and 5 to 8 are from another unique visitor, below is the computation.
Search Engines
Search Engines Report is again based on the referrer. Adobe has its own search engine catalogue and when the domain of the referrer matches the catalogue, the line item will be classified under Search Engines (With proper name). If not, the line item will be classified as unspecified.
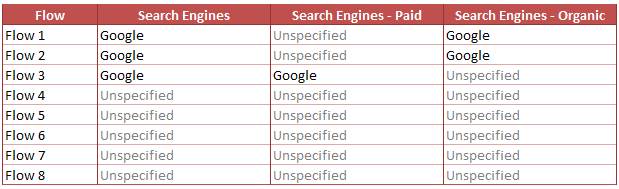
Within Search Engines Report, we also have sub classifications Search Engines – Paid and Search Engines – Natural.
Search Engines – Paid is based on the ‘Paid Search Detection Rules’ in Adobe Analytics. It uses Search Engines along with URL Query String Identifier to classify the Paid. Search Engines Reports will look like the below if we consider ‘gclid’ as the URL Query String Identifier inside the ‘Paid Search Detection Rules’. Note that URL Query String Identifier should be on our landing URL and not on the referrer.
Search Keywords
Search Keywords Report is based both on the referrer and referrer Query String Identifier ‘q’. If the domain of the referrer matches the search engine catalogue and the referrer has the Query String Identifier ‘q’, Query String Identifier Value is captured and stored in the report.
Within Search Keywords Report, we also have sub classifications Search Keywords – Paid and Search Keywords – Natural. Both the reports are identical as Search Engines Classification and thus the results will look like the below i.e. Based on ‘Paid Search Detection Rules’.
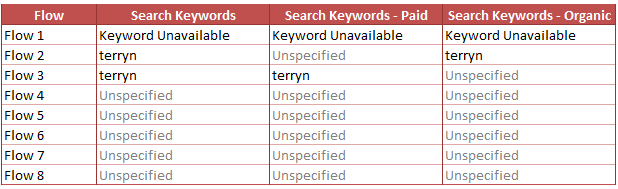
If the referring domain matches the search engine catalogue but without the referrer Query String Identifier ‘q’, the result will be ‘Keyword Unavailable’. When referring domain didn’t match the search engine catalogue, the result will be ‘Unspecified’ even if the referrer has the Query String Identifier ‘q’.
Referrer Type
Last but the most important report in Traffic Sources and one more time, the report is based on the referrer. Adobe has its own referring domain catalogue and when the domain of the referrer matches the catalogue, the line item will be classified under the referrer type report. The catalogue and the results will look something like the below.


In general, if we need Organic and Paid Channels Classifications based on traffic sources, it is available only for Search Engines but the configuration options are limited unlike Marketing Channels. However, the limitations are not for creating the segments and thus the reports are super useful when your didn’t configure Marketing Channels. Enjoy using Traffic Sources Report to analyze critical aspects of visitor behavior.



